When a workflow includes tasks that are executed more times, consider whether it is appropriate to use the For Statement, i.e. the pair of operators OPH_FOR and OPH_ENDFOR.
Unlike other Ophidia operators, they does not operate on data or metadata, but they could be adopted to set particular flow control rules for the Workflow manager. In particular, the operator OPH_FOR (OPH_ENDFOR) is used to begin (end) a sub-section that has to be executed several times. Each cycle is associated with a tag (and a numeric index, i.e. a counter) that may be also used to define the values of inner task arguments. Values of both tag and index are set as an argument of the operator OPH_FOR.
For example, consider the following workflow, applied to a cube containing time series with 12 elements (months).
{
"name": "Example6",
"author": "Foo",
"abstract": "Simple workflow with a cycle",
"exec_mode": "sync",
"ncores": "1",
"cube": "http://hostname/1/1",
"tasks":
[
{
"name": "Begin loop on months",
"operator": "oph_for",
"arguments":
[
"name=index",
"counter=1:12",
"values=Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec"
]
},
{
"name": "Extract a month",
"operator": "oph_subset",
"arguments":
[
"subset_dims=time",
"subset_filter=&{index}"
],
"dependencies": [ { "task": "Begin loop on months" } ]
},
{
"name": "End loop on months",
"operator": "oph_endfor",
"arguments": [ ],
"dependencies": [ { "task": "Extract a month" } ]
}
]
}
The workflow is composed by only three tasks, but the task named Extract a month is executed 12 times before the workflow execution ends. For each loop the value of the counter named index is set to a different integer value in range 1:12 and used to update the argument subset_filter: a different element of time series of input cube is then extracted. The parameter values of OPH_FOR is an ordered list of tags, one for each cycle, which is not exploited in this case.
In Example6 the input of each subsetting operation is the cube http://hostname/1/1 because task dependencies are embedded and, hence, the parameter cube is set to default value. However, it is admitted the input cube used during a cycle can be the output cube of the previous loop as in the following example.
{
"name": "Example7",
"author": "Foo",
"abstract": "Simple workflow with a cycle",
"exec_mode": "sync",
"ncores": "1",
"cube": "http://hostname/1/1",
"tasks":
[
{
"name": "Begin loop on months",
"operator": "oph_for",
"arguments":
[
"name=index",
"counter=1:100"
]
},
{
"name": "Extract a month",
"operator": "oph_apply",
"arguments":
[
"query=oph_predicate(measure,'1','>0','x^2-1','')",
"measure_type=auto"
],
"dependencies":
[ { "task": "Begin loop on months", "type": "single" } ]
},
{
"name": "End loop on months",
"operator": "oph_endfor",
"arguments": [ ],
"dependencies":
[ { "task": "Extract a month", "type": "single" } ]
}
]
}
In Example7 the loop iterations have to be executed sequentially due to the data dependency across them; conversely the tasks in Example6 could be executed in parallel as the input data is the same cube. Hence, to reduce execution time the operator OPH_FOR has been adapted in order to transform the original workflow in a version in which the loop is substituted by a number of independent branches that can be executed in parallel: this is the Parallel For Statement.
The For statement consists of a pair of Ophidia operators, OPH_FOR and OPH_ENDFOR, used to repeat the execution of one or more (even dependent) tasks of a workflow over different input data.
The operator OPH_FOR is used to configure the iterative block and, in particular, to set the number N of loops to be executed. By this aim, the user has to provide an ordered list of N labels to be assigned to cycles so as to distinguish one cycle from another one. The list is assigned to the parameter values of the operator, separating each value by |. Alternatively (or in addition), the user could set a list of N indexes using the notation adopted in Ophidia for subsetting strings. For example, the notation 1:12 means the integers between 1 and 12. Index list is assigned to parameter counter of the operator. A name has to associated with the counter by setting the parameter name: it should comply with IEEE Std 1003.1-2001 conventions, unless brackets {} are adopted to refer it. The syntax used to set variables with OPH_SET can be also adopted as described here.
The tasks to be repeated (inner tasks) have to depend on OPH_FOR directly or indirectly, namely they depend on other tasks in the iterative block. Setting the parameters of these tasks the user is enabled to exploit the value of label or counter associated with current iteration. In fact, during the execution, the current value of the label is represented by @name or @{name}, whereas current value of the counter is &name or &{name}. These codes can be used in the definition of the inner tasks as programming variables.
The operator OPH_ENDFOR ends an iterative block, depends on inner tasks (directly or indirectly) and has no parameters.
Although inner tasks may be executed in parallel according to their interdependencies, cycles are executed sequentially and, in particular, a new iteration is started only when every dependency of task OPH_ENDFOR is satisfied. Whenever this happens, the Workflow engine appends the references to inner task outputs (e.g. PID of new cubes) to JSON Response, resets the status of inner tasks and updates the values of label and counter to next ones in related lists. Of course, in case of the last iteration the iterative block (OPH_ENDFOR included) is considered completed and the workflow execution goes on.
In case OPH_FOR depends on a data operator, the PID of output cube is considered an input for OPH_FOR. The operator does not process the cube, but rather transfers it to dependent tasks (which may then process it). Similarly, OPH_ENDFOR can gather PIDs of cubes generated by inner tasks and transfers them to next tasks, however this happen only in the last iteration. During the loop the PIDs gathered by OPH_ENDFOR are set as output of OPH_FOR in next iteration, so that it is possible to define data dependencies among successive iteration (exploited in the workflow Example7).
Multiple For statements can be used in the same workflow. The iterative blocks can be even nested and the values of the parameter of the inner statements could depend on the tags and the indexes set in outer ones. In general, the scope of tags and indexes is similar to that used in traditional imperative programming.
As an example, consider the workflow.
{
"name": "Example8",
"author": "Foo",
"abstract": "Workflow with a cycle",
"exec_mode": "async",
"ncores": "1",
"tasks":
[
{
"name": "Import",
"operator": "oph_importnc",
"arguments":
[
"src_path=/path/to/file.nc",
"measure=random"
]
},
{
"name": "Begin loop on months",
"operator": "oph_for",
"arguments":
[
"name=index",
"counter=1:12"
],
"dependencies": [ { "task": "Import" } ]
},
{
"name": "Extract a month",
"operator": "oph_subset",
"arguments":
[
"subset_dims=time",
"subset_filter=&{index}"
],
"dependencies":
[
{ "task": "Import", "type": "single" },
{ "task": "Begin loop on months" }
]
},
{
"name": "Spatial reduction",
"operator": "oph_aggregate",
"arguments": [ "operation=avg" ],
"dependencies":
[ { "task": "Extract a month", "type": "single" } ]
},
{
"name": "End loop on months",
"operator": "oph_endfor",
"arguments": [ ],
"dependencies":
[ { "task": "Spatial reduction" } ]
},
{
"name": "Deletion",
"operator": "oph_delete",
"arguments": [ ],
"dependencies":
[
{ "task": "Import", "type": "single" },
{ "task": "End loop on months" }
]
}
]
}
This workflow is composed by three sections:
The output of the command check is shown in the following figure (A). To emphasize the statement the iterative block is encircled by a square and flow control operators are shown in a hexagon rather than a circle.
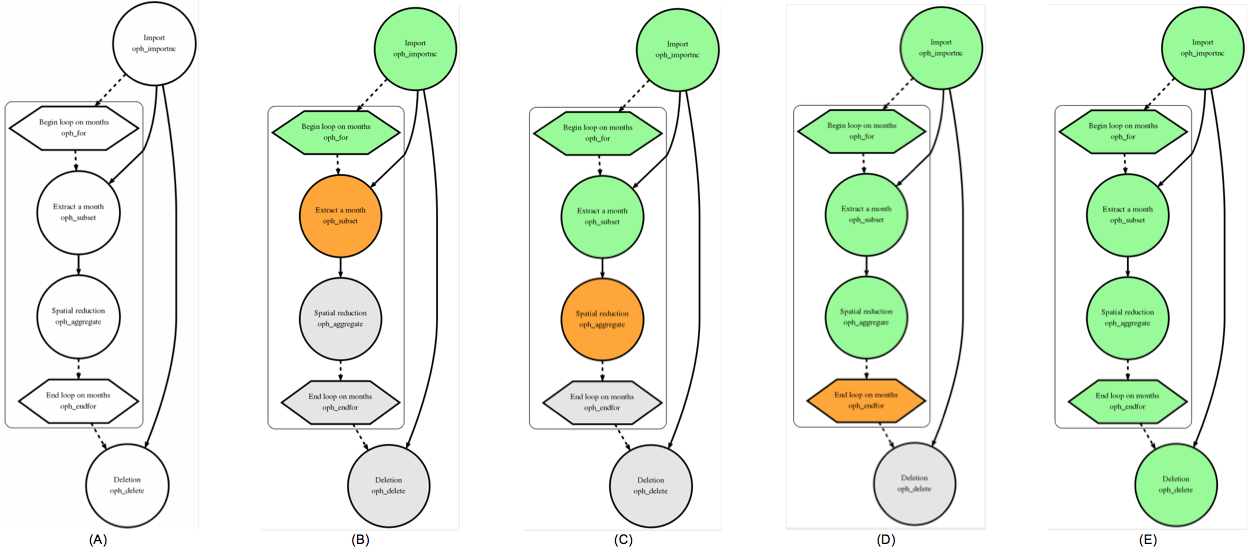
Figures show a set of snapshots of workflow status (the output of command view) during the execution of Example8 and, in particular
It is interesting to note that the circle associated to task Spatial reduction is green (the task is considered Completed) at the end of an iteration and it becomes orange (Running) at the begin of the next iteration.
In general the For statement can be exploited to concisely describe a sub-workflow that has to be re-executed several times. Iterations are executed sequentially because the data obtained in a cycle could be processed in next cycles. If this feature is not exploited, iterations could be executed in parallel and, provided that resources are available, workflow execution time would be reduced. This possibility is offered by the option parallel of the operator OPH_FOR.
If the option is enabled for a task OPH_FOR (setting parallel=yes), the engine, before executing the workflow, transforms it into an equivalent version in which iterative blocks are expanded into N independent sub-workflows, where N is the number of initial iterations. The new workflow is then executed taking the usual rules based on task dependencies into account.
For example, consider the workflow in Example6. There exists no dependency among tasks in different iterations as well as output of each iteration is not processed in other iterations, so that option parallel could be set as follows.
{
"name": "Begin loop on months",
"operator": "oph_for",
"arguments":
[
"parallel=yes",
"name=index",
"counter=1:12",
"values=Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec"
]
}
Upon the JSON Request has to processed, the Workflow engine converts the workflow as shown in the following figure, which reports the output of command view at the end of workflow execution.

Note that a numerical suffix has been appended to original names of inner tasks because, in the new workflow, tasks are replicated but the name of each reply has to be unique.
As shown in Figure, the substitution results in a sort of massive operation in which each branch is a sub-task. Actually, the statement can be considered a generalization of massive operations, because an iterative block may include more than one task, indeed, in general, it may contain a sub-workflow. The operator therefore allows to implement a kind of massive workflow.
In addition, also in this case several statements can be used and even nested in the same workflow.
